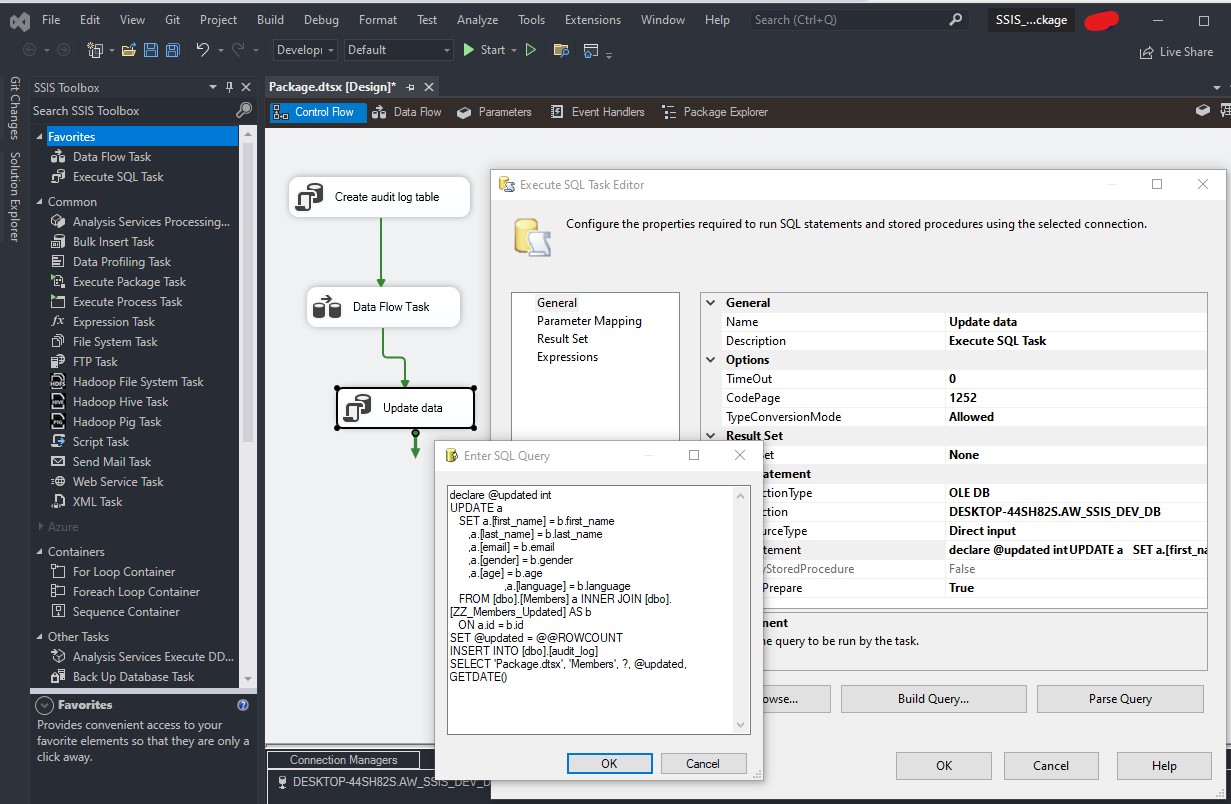
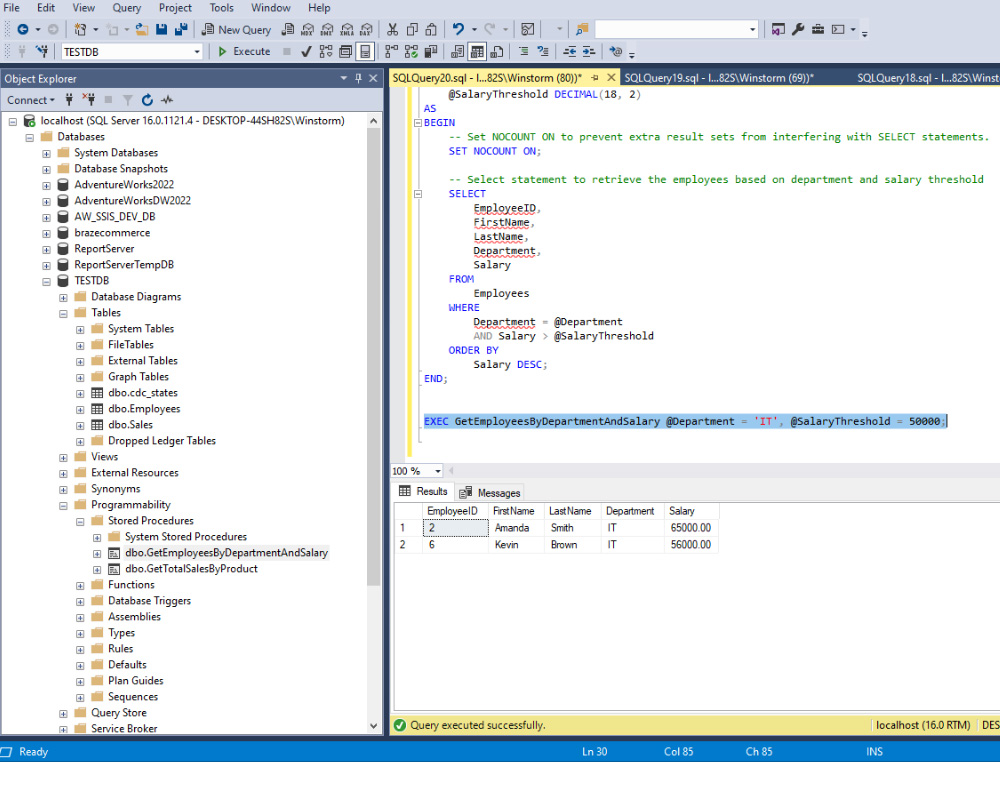
Stored Procedures in SQL Server Stored Procedures in SQL Server serve as precompiled collections of SQL statements that can be executed as a single unit, providing a powerful way to encapsulate business logic within the database. The primary benefits of Stored Procedures include improved performance due to precompilation and caching of execution plans, enhanced security […]
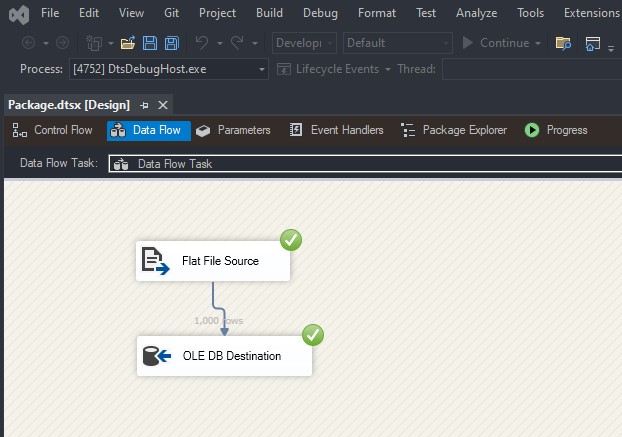
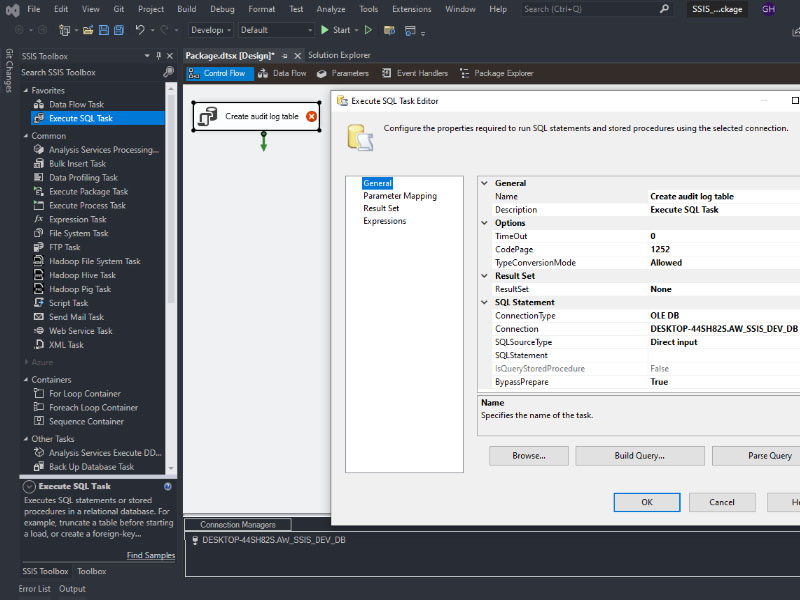
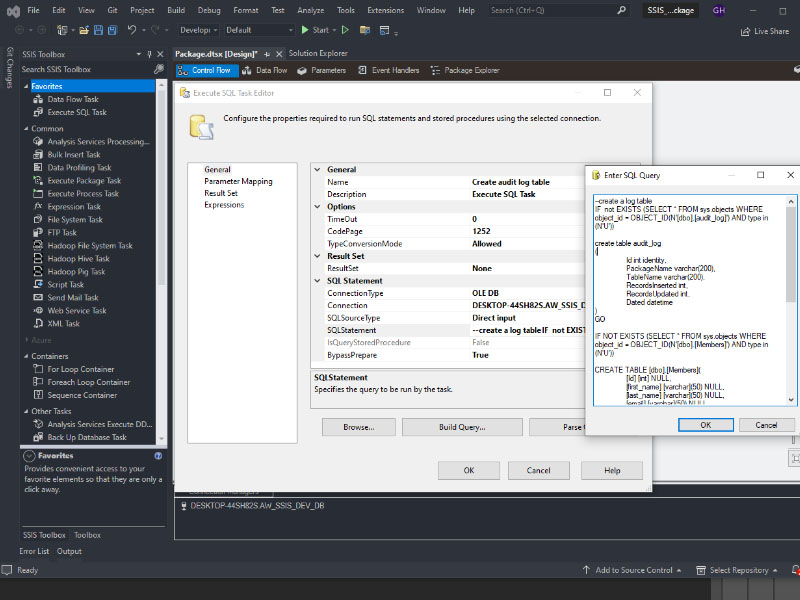
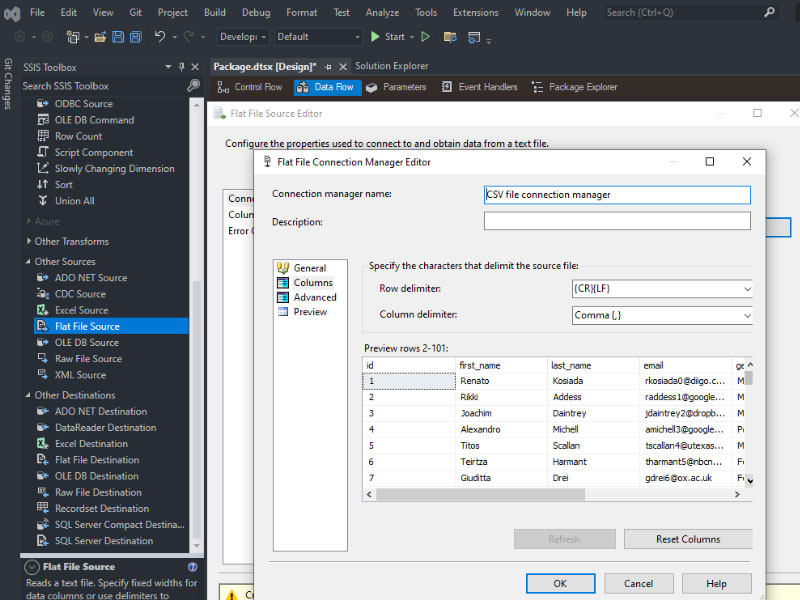
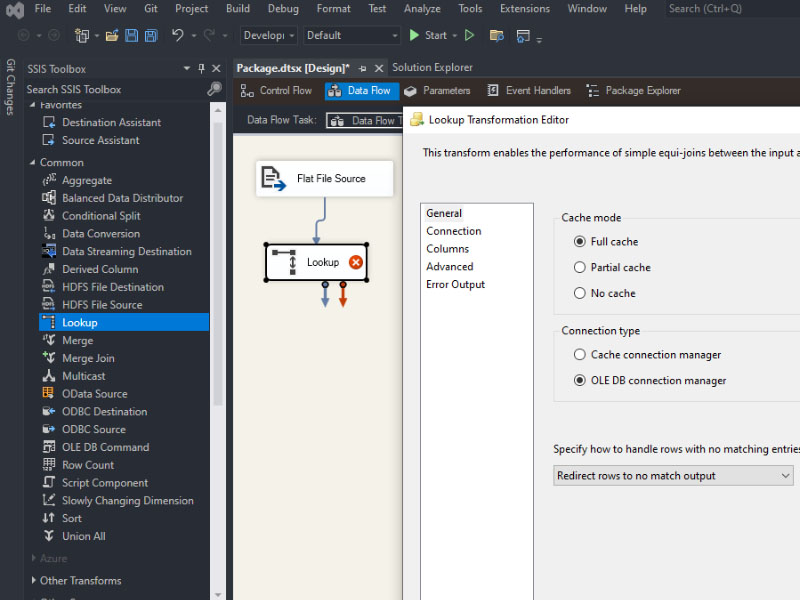
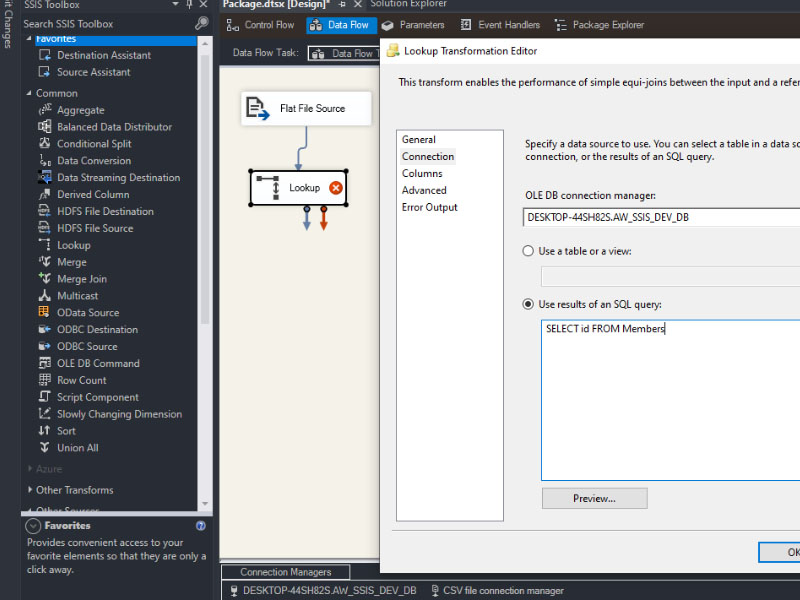
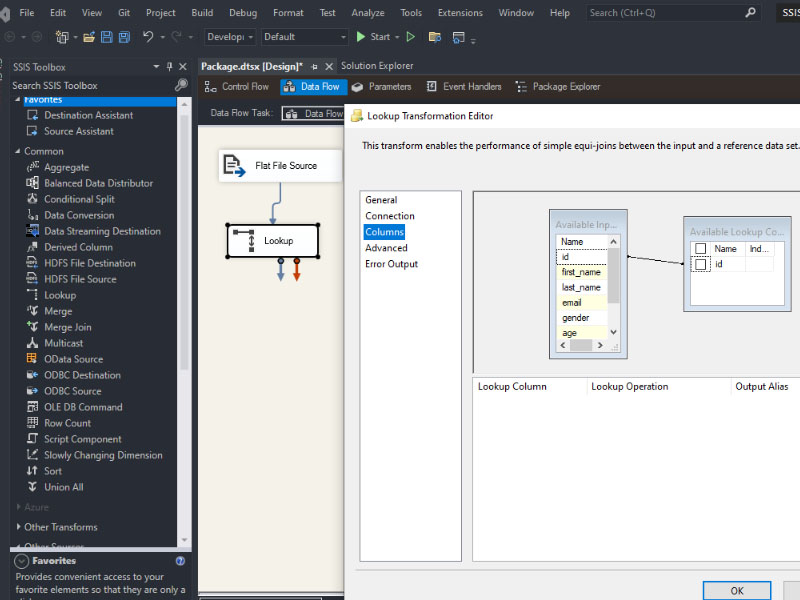
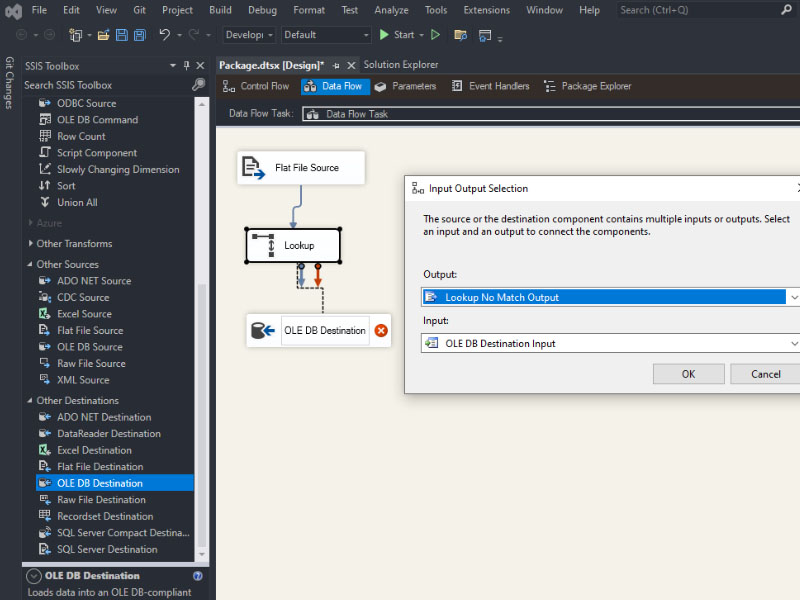
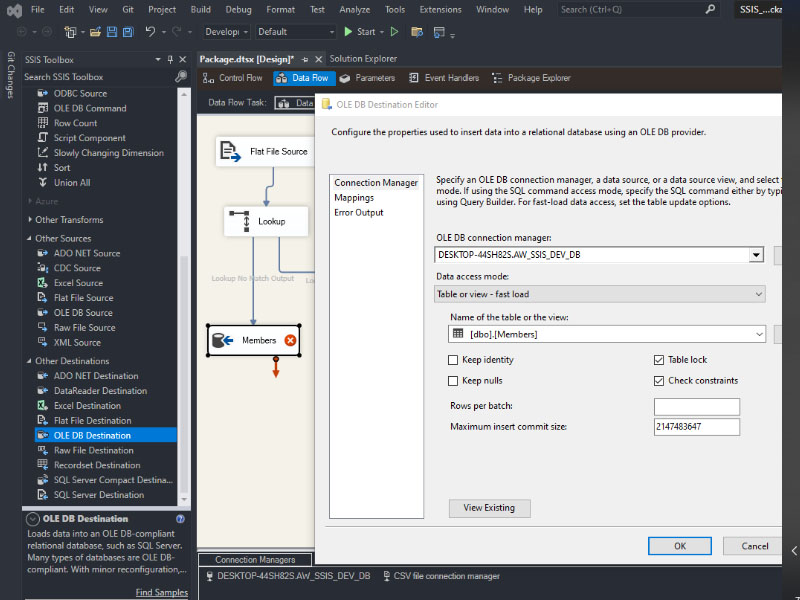
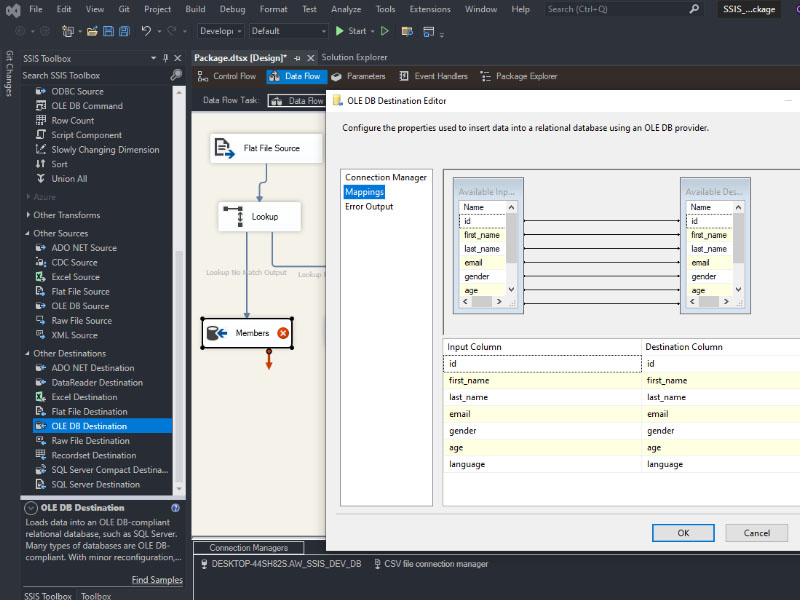
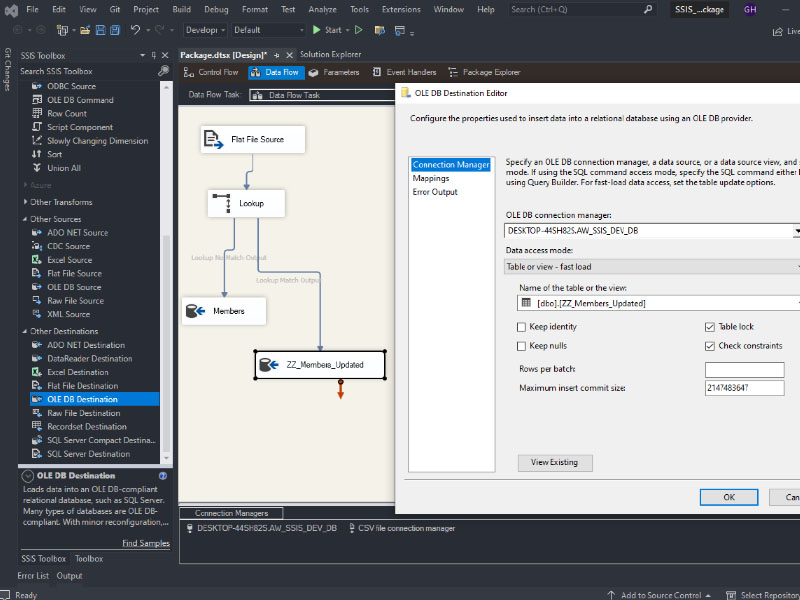
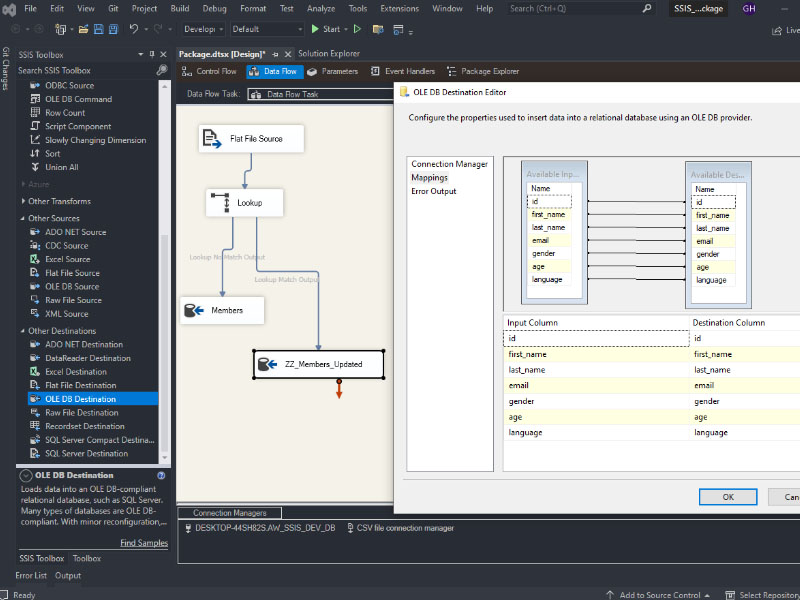
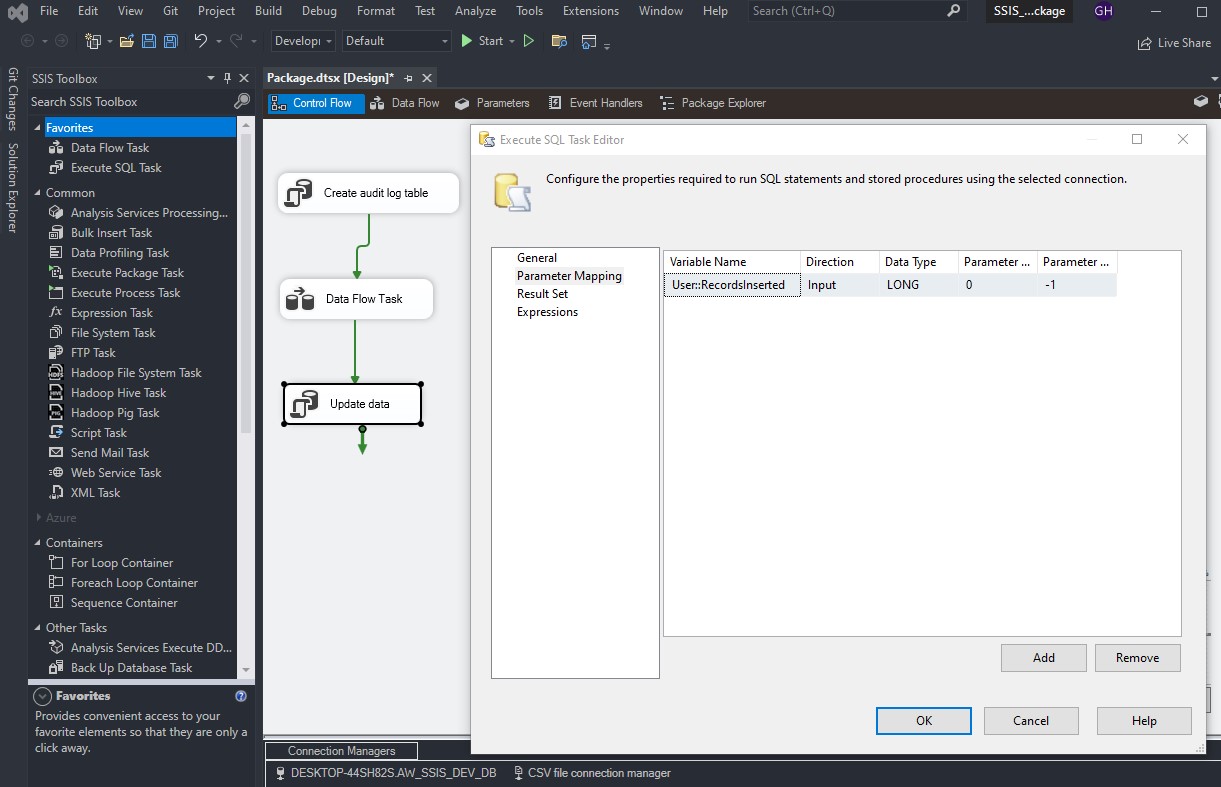
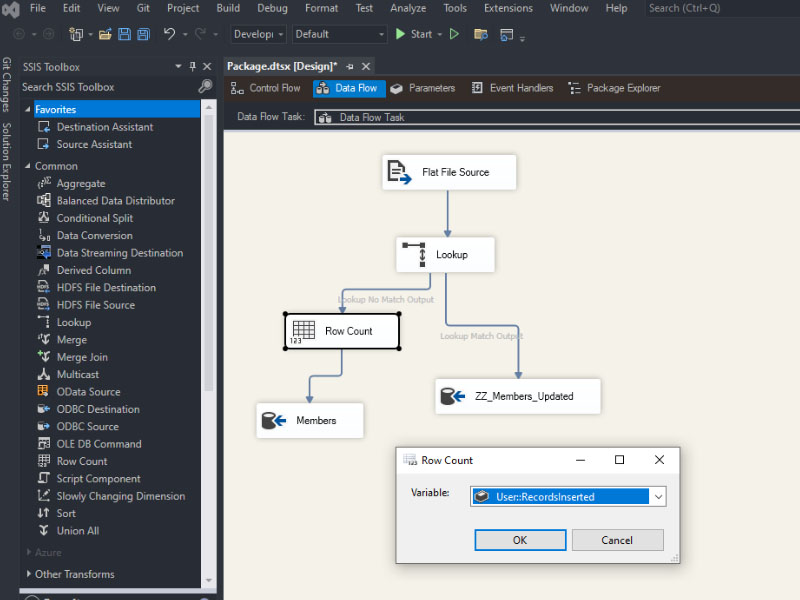
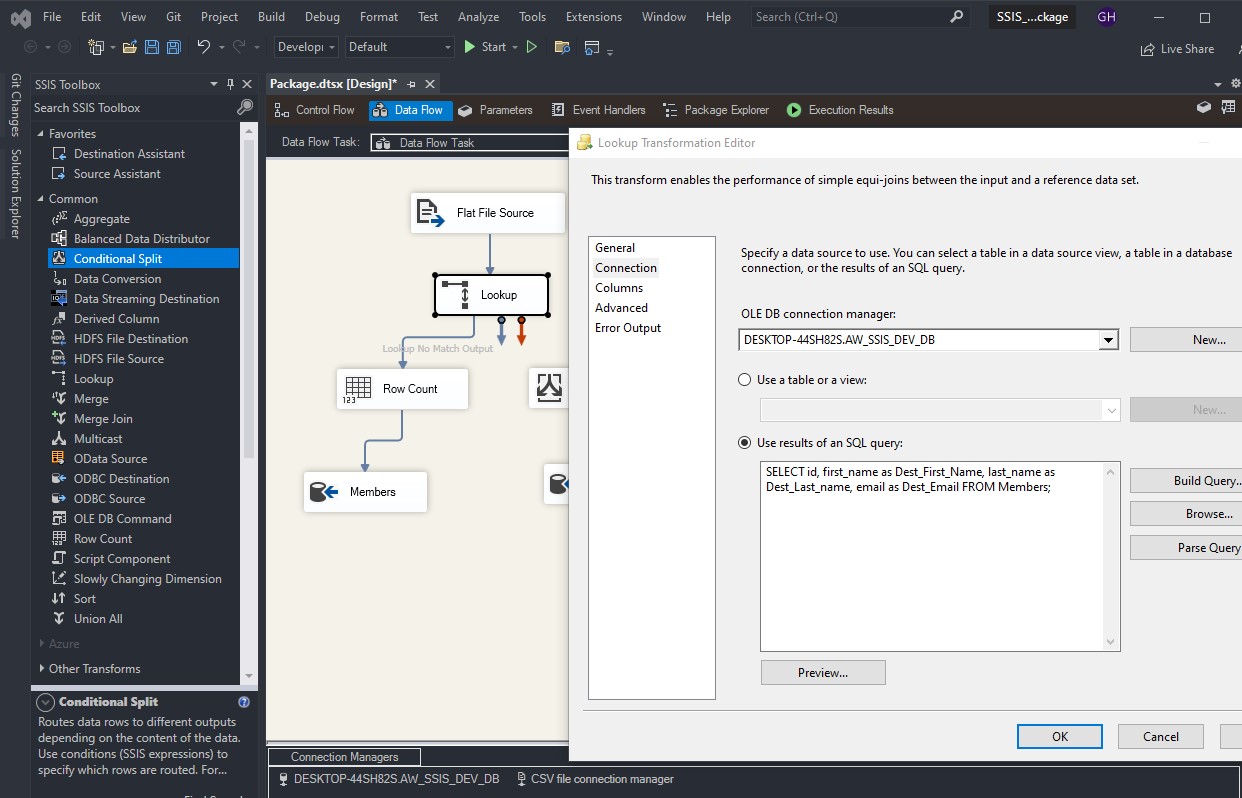
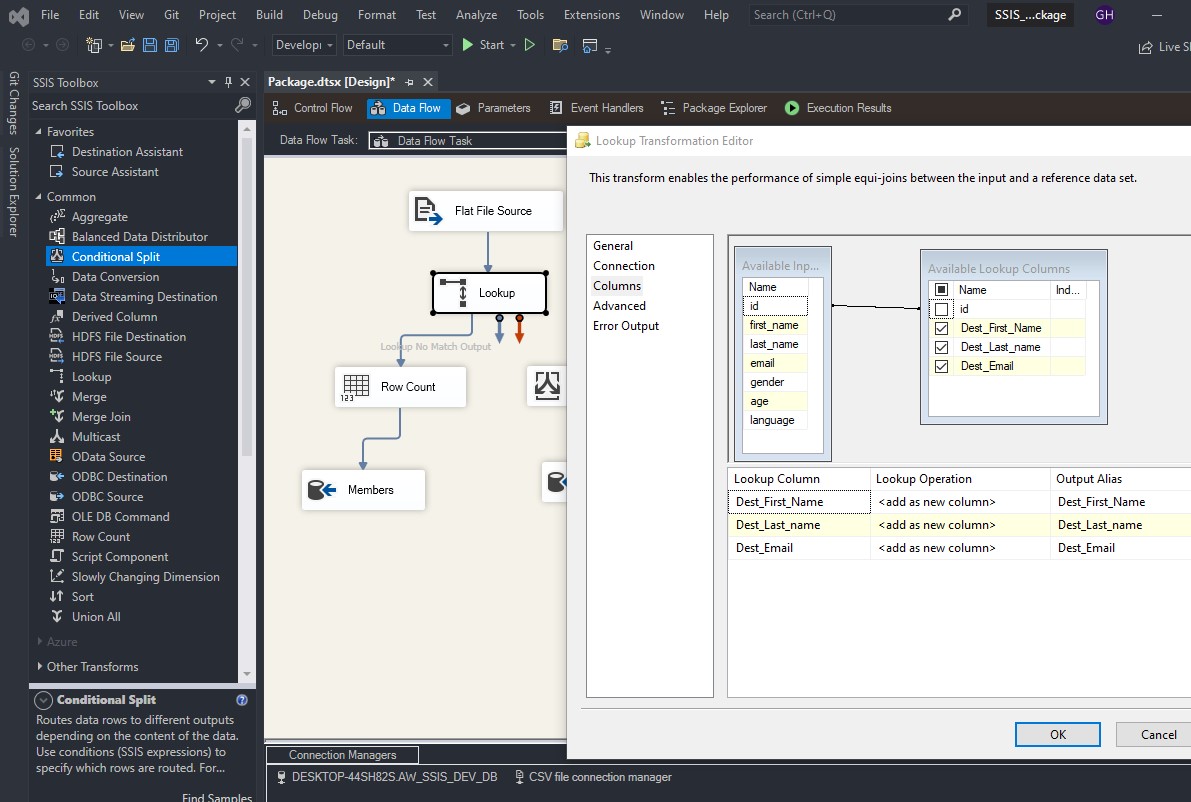
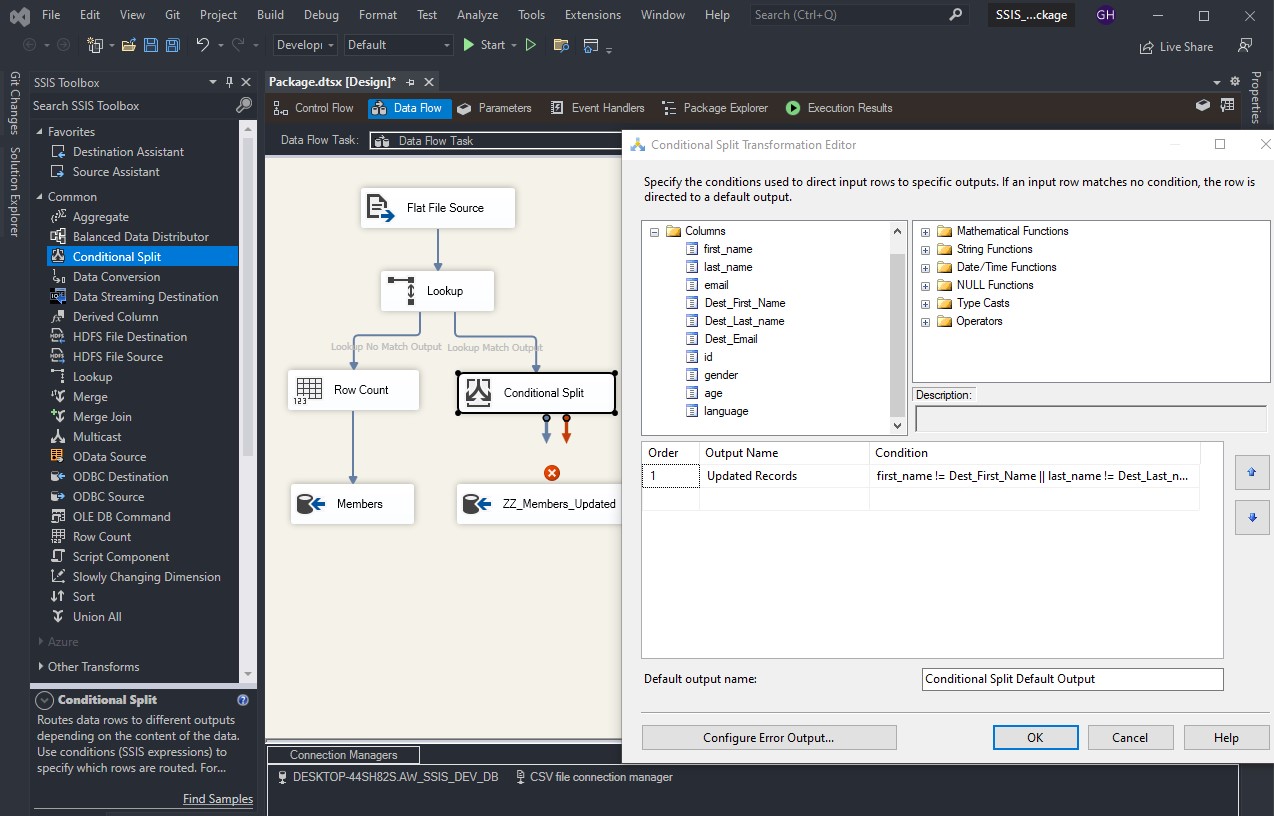
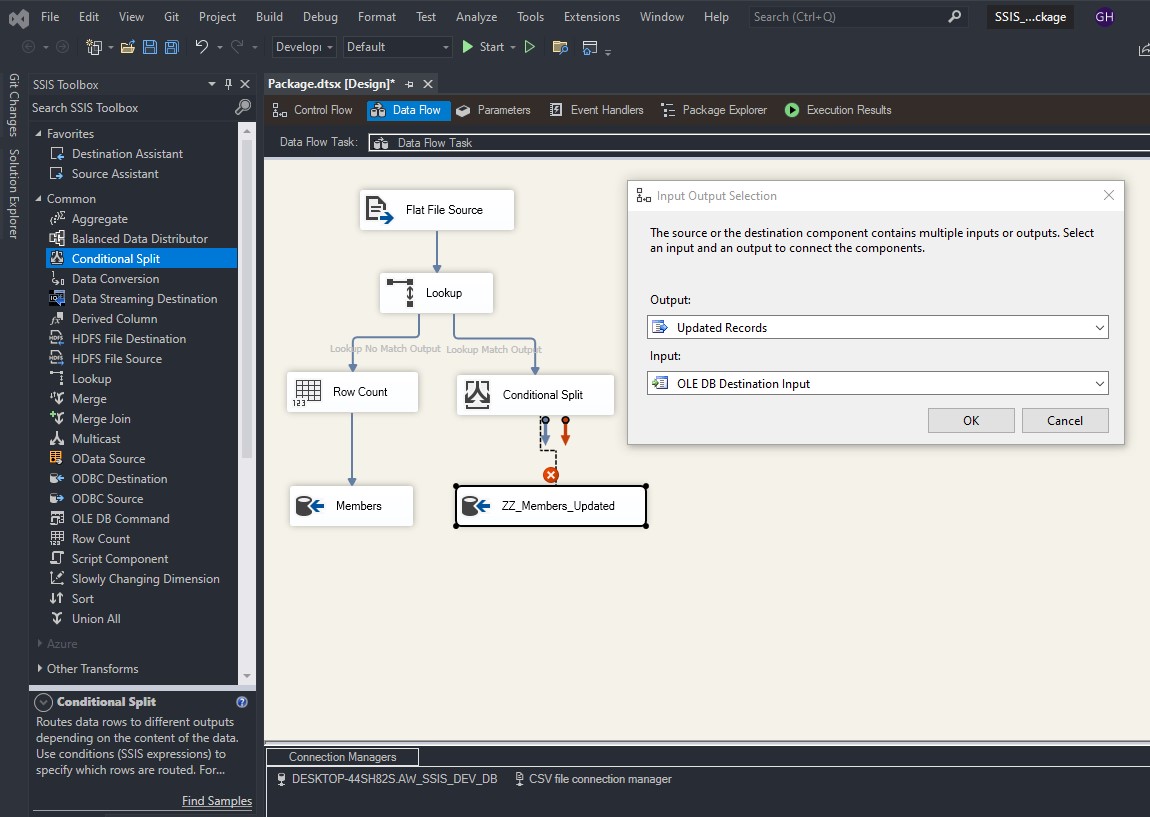
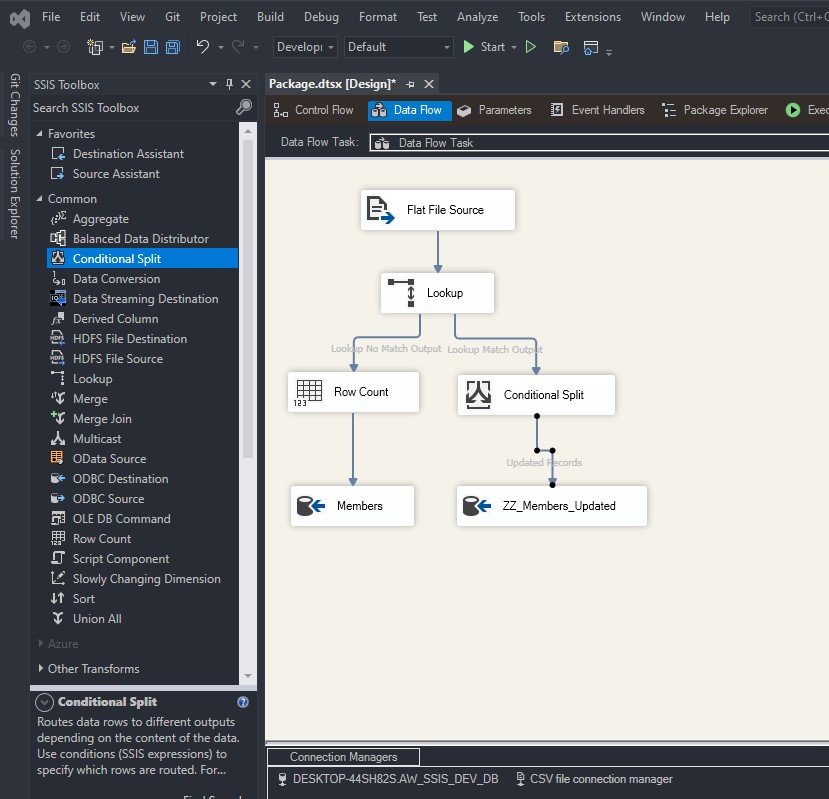
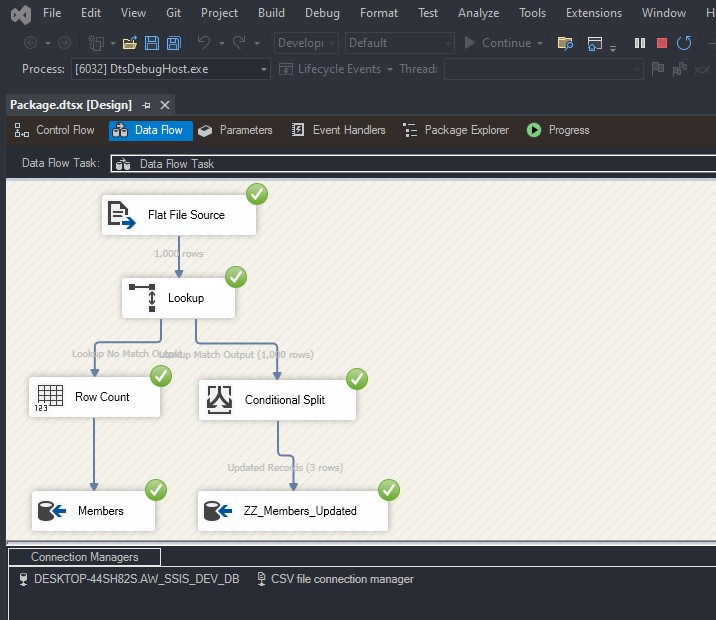
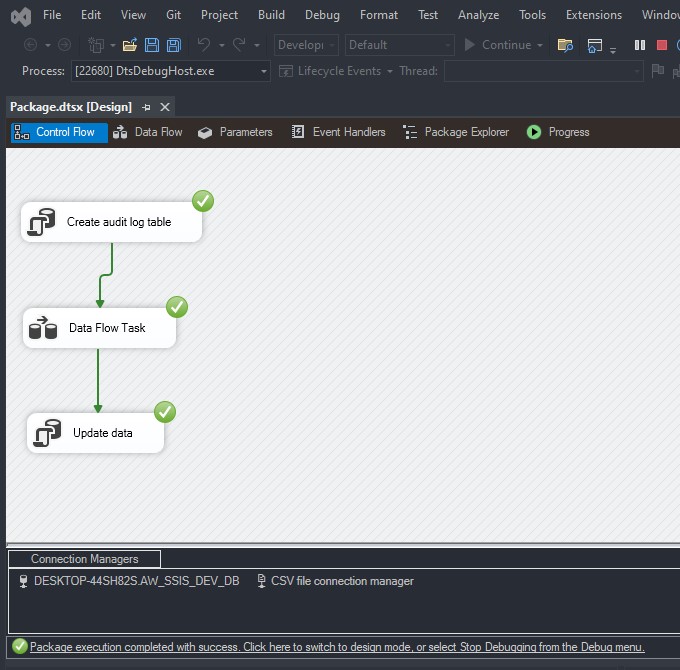
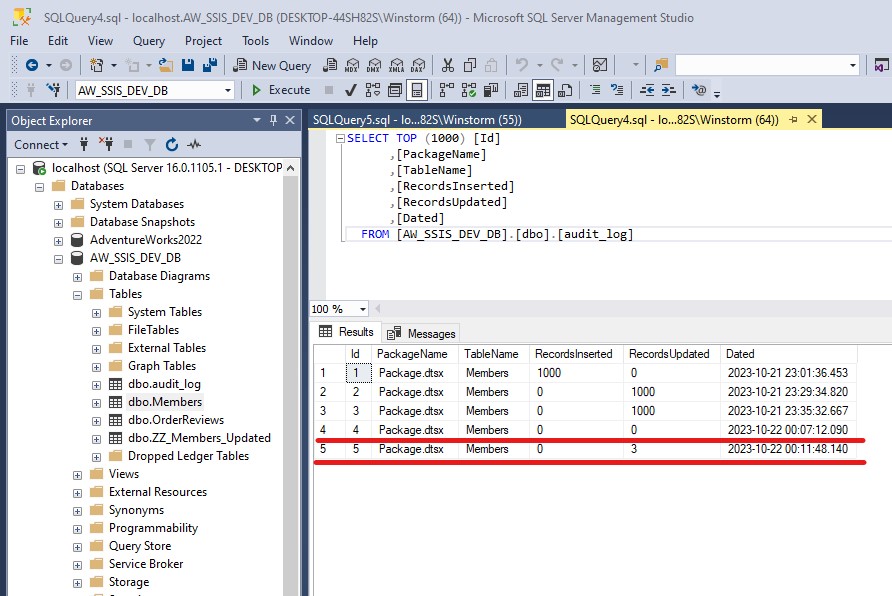
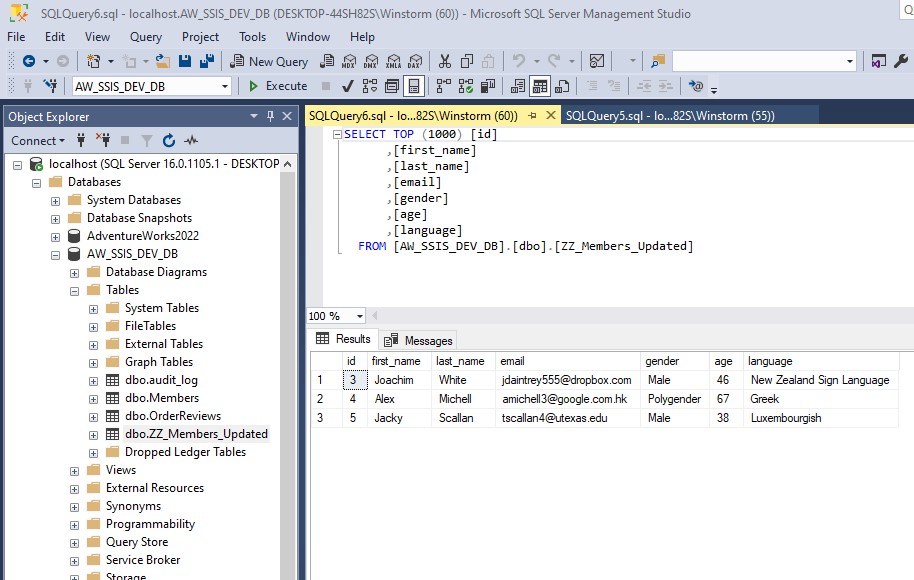
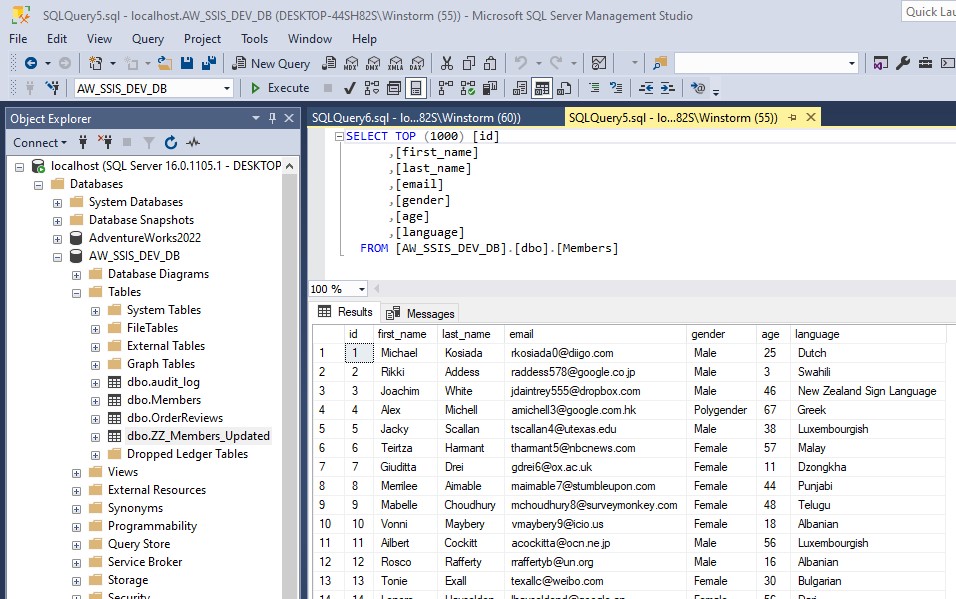
To load a CSV file into SQL Server using SSIS, follow these steps: Create a table on SQL server: Create a new Integration Services Project: Launch Microsoft Visual Studio and create a new Integration Services Project. Rename the default package to something meaningful, such as “Load CSV File into SQL Server”. Setup Connection Managers: At […]
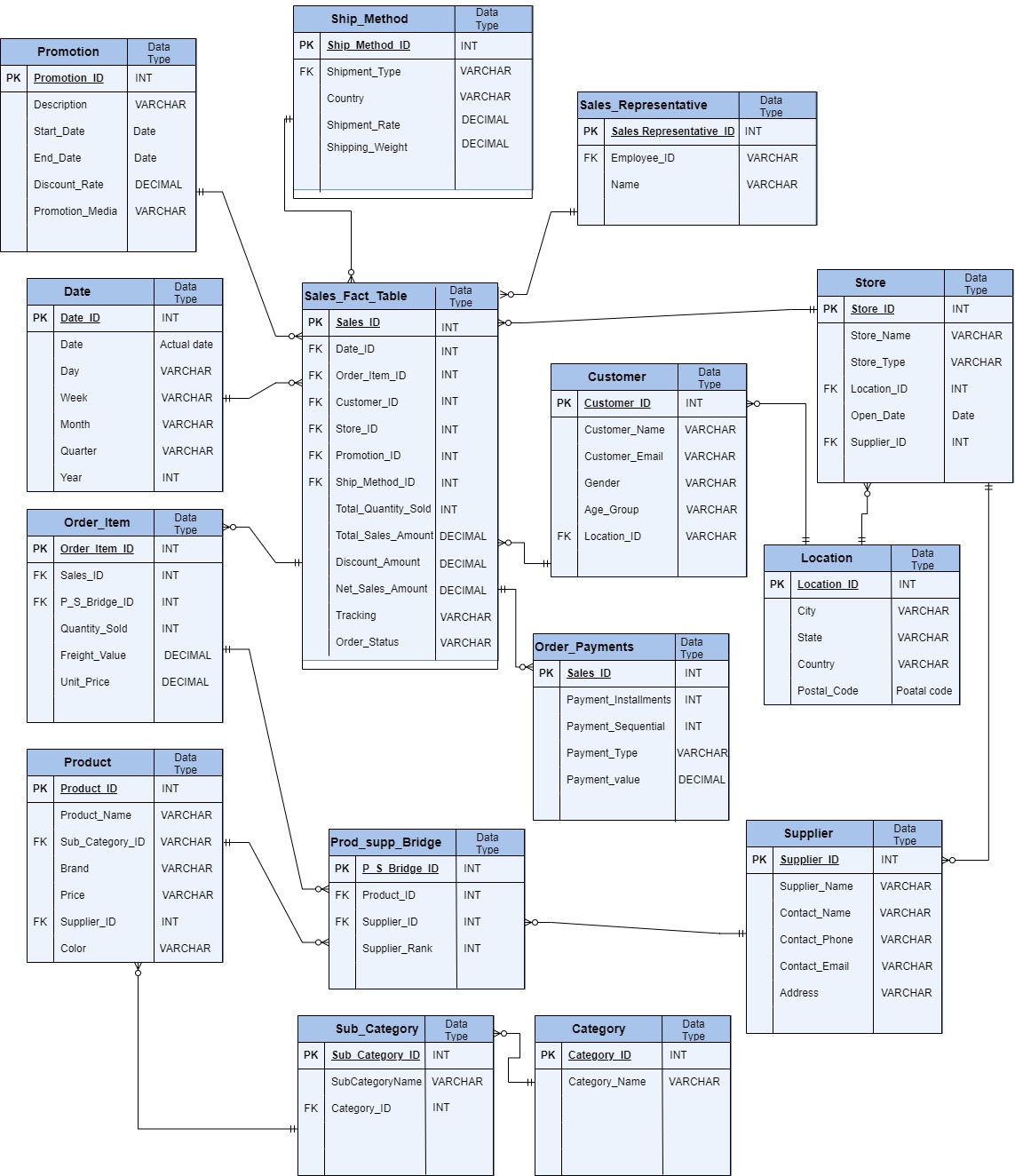
Effective Table Creation Strategies for Data Warehouses Creating tables in a data warehouse is a fundamental step that significantly impacts the entire system’s performance, scalability, and usability. Whether designing a new data warehouse from scratch or optimizing an existing one, effective table creation strategies are essential to ensure that your data is organized, accessible, and […]