Table of Contents
ToggleEffective Table Creation Strategies for Data Warehouses
Creating tables in a data warehouse is a fundamental step that significantly impacts the entire system’s performance, scalability, and usability. Whether designing a new data warehouse from scratch or optimizing an existing one, effective table creation strategies are essential to ensure that your data is organized, accessible, and efficient to query.
Understanding the Role of Tables in a Data Warehouse
Tables in a data warehouse serve as the core structures for storing and managing data. Unlike operational databases, where tables are designed for transactional processing, data warehouse tables are designed for query performance and analytical processing. This difference in purpose necessitates a different approach to table creation.
Data warehouse tables typically fall into two main categories:
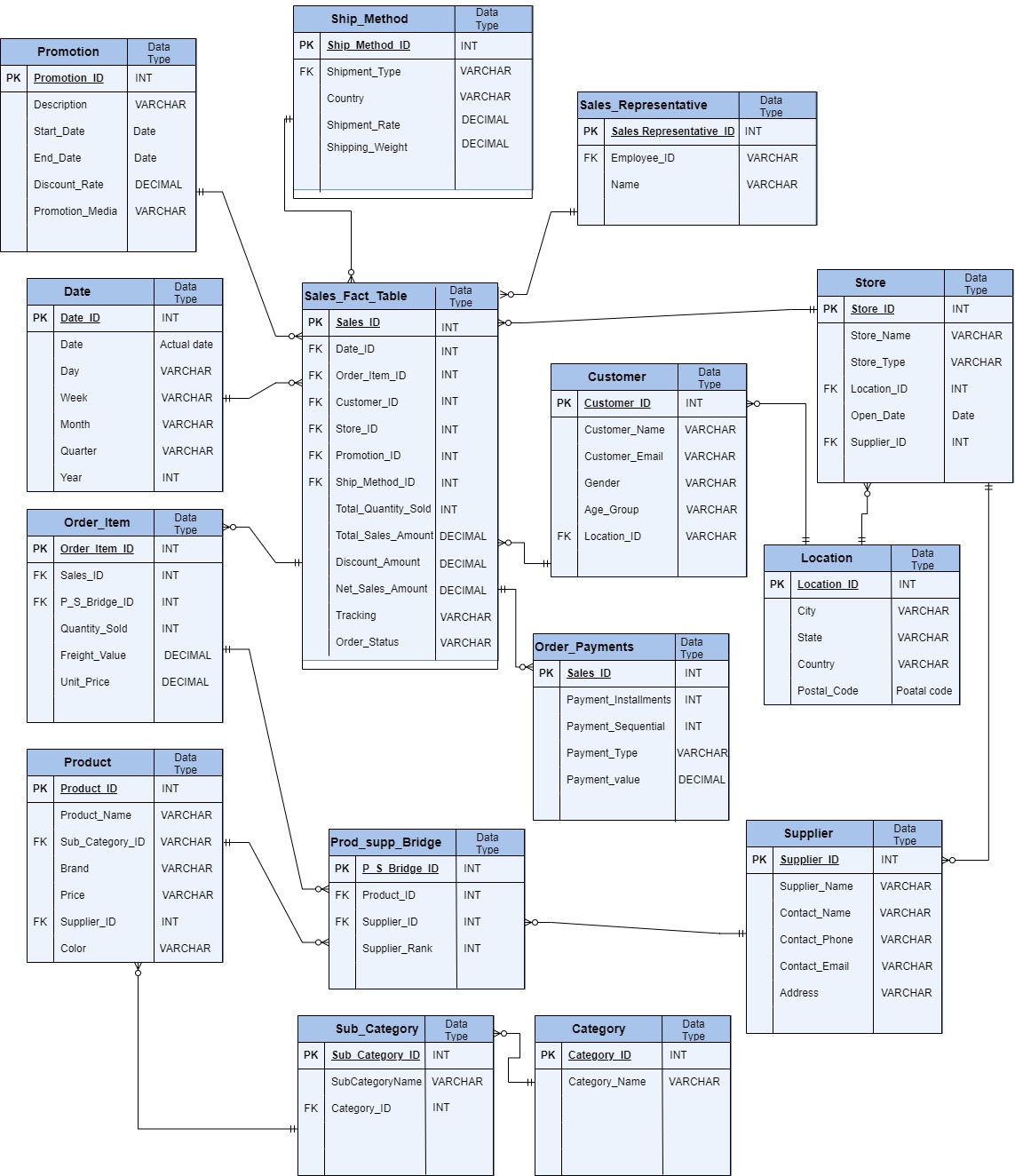
Fact Tables: These tables store quantitative data for analysis and are often the largest tables in the warehouse. They contain measurements, metrics, or facts about a business process, such as sales, revenue, or orders.
Dimension Tables: These tables store descriptive attributes related to the facts, providing context for the data in the fact tables. Examples include customer details, product information, and periods.
Key Strategies for Effective Table Creation
1. Star Schema
- Description: The star schema is the simplest and most commonly used schema in data warehousing. It consists of a central fact table connected to several dimension tables, forming a star-like pattern.
- Components:
- Fact Table: Contains quantitative data for analysis, such as sales, revenue, or performance metrics.
- Dimension Tables: Describe the dimensions (e.g., time, location, product) used to filter, group, and label the facts.
- Use Case: Best for simpler queries and reporting scenarios where speed and ease of use are important.
2. Snowflake Schema
- Description: A variation of the star schema, the snowflake schema normalizes the dimension tables into multiple related tables, creating a more complex structure resembling a snowflake.
- Components:
- Fact Table: Same as in the star schema.
- Normalized Dimension Tables: Dimension tables are split into related tables to reduce redundancy.
- Use Case: Suitable for complex queries and when reducing data redundancy is a priority.
3. Galaxy Schema (Fact Constellation)
- Description: The galaxy schema is a more complex structure that includes multiple fact tables, sharing dimension tables. It’s essentially a collection of star schemas.
- Components:
- Multiple Fact Tables: Represent different business processes.
- Shared Dimension Tables: Common dimensions that link multiple fact tables.
- Use Case: Ideal for large organizations with multiple business processes that need to be analyzed together.
4. Data Vault
- Description: The Data Vault is a more advanced and flexible schema designed to handle changes over time and ensure scalability. It consists of three core components: hubs, links, and satellites.
- Components:
- Hubs: Store unique business keys (e.g., customer IDs).
- Links: Capture relationships between business keys.
- Satellites: Store descriptive attributes and time-variant data.
- Use Case: Best for organizations that require a scalable, agile data warehouse with historical tracking and auditing capabilities.
5. Normalized Structure (Third Normal Form)
- Description: A fully normalized structure where data is stored without redundancy. Data is broken down into smaller, related tables, following normalization rules (1NF, 2NF, 3NF).
- Components:
- Normalized Tables: Each table stores data in its most granular form.
- Relationships: Defined by foreign keys connecting tables.
- Use Case: Used when the focus is on reducing redundancy and ensuring data integrity, but might be less performant for complex queries.
6. Hybrid Schema
- Description: A combination of different schemas (e.g., star and snowflake) to balance performance and normalization.
- Components:
- Fact and Dimension Tables: Mix of normalized and denormalized tables.
- Use Case: When different parts of the data warehouse require different levels of normalization.
7. Flat Tables
- Description: A flat table schema involves storing all data in a single, large table without any normalization.
- Components:
- Single Table: Contains all necessary fields.
- Use Case: Simplifies data access and is used in small-scale applications or where performance isn’t a concern, but it lacks scalability and flexibility.
8. Data Mart
- Description: A data mart is a smaller, more focused version of a data warehouse, typically aimed at serving a specific department or business unit.
- Components:
- Fact and Dimension Tables: Similar to a star schema but limited in scope.
- Use Case: Useful for smaller, department-specific reporting and analytics.
9. Inmon’s Corporate Information Factory (CIF)
- Description: This approach advocates for a top-down, enterprise-wide data warehouse design with normalized structures and data marts for individual departments.
- Components:
- Normalized Data Warehouse: Acts as a central repository.
- Data Marts: Created for specific departments, often denormalized.
- Use Case: Suitable for large organizations needing an enterprise-wide view with the ability to drill down into department-specific details.
10. Kimball’s Dimensional Modeling
- Description: A bottom-up approach where data marts are built first, and then combined to create an enterprise data warehouse.
- Components:
- Star or Snowflake Schema: Used in data marts.
- Conformed Dimensions: Ensures consistency across data marts.
- Use Case: Best for organizations that want to deliver quick results and grow their data warehouse over time.
Choosing the Right Structure
- Simple Reporting Needs: Star Schema, Flat Tables.
- Complex Analytical Requirements: Snowflake Schema, Galaxy Schema.
- Scalability and Flexibility: Data Vault, Hybrid Schema.
- Department-Specific Reporting: Data Mart.
- Enterprise-Wide Analysis: Inmon’s CIF, Kimball’s Dimensional Modeling.
Additional Considerations
- ETL Processes: Design efficient ETL (Extract, Transform, Load) processes to populate the data warehouse.
- Data Governance: Implement governance policies to ensure data quality, security, and compliance.
- Performance Optimization: Indexing, partitioning, and materialized views can enhance performance.
Effective table creation is the cornerstone of a successful data warehouse. By carefully designing tables with performance, scalability, and data integrity in mind, you can create a data warehouse that not only meets your current analytical needs but also adapts to future demands. Through thoughtful consideration of schema design, indexing, partitioning, and storage optimization, you ensure that your data warehouse delivers timely, accurate insights that drive informed decision-making.