Data mining is a process of discovering patterns, correlations, or useful information from large sets of structured or unstructured data to extract valuable insights. It combines various techniques from statistics, machine learning, and database management to uncover hidden patterns and relationships within the data. Data mining is a crucial component of the broader field of data science and plays a significant role in business, research, and decision-making processes.
Table of Contents
ToggleKey Concepts in Data Mining
1. Data Preparation:
Data mining begins with collecting and preparing data from different sources. This step involves cleaning the data, handling missing values, and transforming data into a suitable format for analysis.
2. Data Exploration:
Exploratory Data Analysis (EDA) is conducted to understand the characteristics of the data. Visualization tools and statistical techniques are used to identify trends, outliers, and patterns within the dataset.
3. Data Mining Techniques
3.1 Classification:
Classification algorithms are used to categorize data into predefined classes or labels. Common techniques include decision trees, support vector machines, and neural networks.
– fraud detection
– customer segmentation
– spam filtering
– risk assessment
– sentiment analysis
3.2 Clustering:
Clustering algorithms group similar data points together based on their characteristics, identifying inherent patterns within the data. K-means clustering and hierarchical clustering are popular methods.
Raw data —–> CLUSTERING ALGORITHMS ——> Clusters of Data
– marketing segmentation
– image processing
– anomaly detection
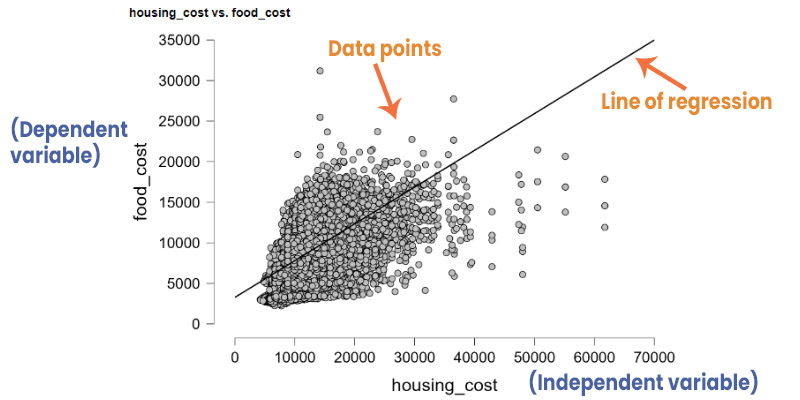
3.3 Regression:
Regression analysis predicts numerical values based on historical data. It is useful for forecasting and trend analysis.
Establish a relationship between a dependent variable and one or more independent variables.
dependent variable = response variable
independent variable = predictor variable or features
simple linear regression:
one independent variable relationship among variables is linear.
multiple linear regression:
more than one independent variables relationship among variables is linear.
determine the dependent variable based on multiple independent variables.
3.4 Association Rule Mining:
This technique identifies relationships and associations among different variables in the dataset. Apriori algorithm is commonly used for association rule mining.
– Antecedent (or left-hand side) variables; antecedent variables precede the consequent variables.
– Consequent (or right-hand side) variables; consequent variables follow the antecedent variables.
– frequency of co-occurrence of variables in a dataset, identifying the patterns or rules that occur most frequently.
– market, basket analysis, example: co-occurrence of products in customer transactions.
3.5 Text Mining:
It is involves analyzing and extracting useful information from unstructured textual data.
Example: emails, social media posts, customer reviews, and news articles.
To analysis data mining techniques which is commonly used sentiment analysis, topic modeling, and content classification.
3.6 Time series analysis:
Time series analysis is a statistical technique used to analyze and interpret data points collected or recorded at specific time intervals. It involves studying the patterns, trends, and behaviors within the data to make predictions or forecasts about future values. Time series data can be found in various fields, such as finance, economics, weather forecasting, and signal processing.
Analyzing time series data helps in understanding historical patterns, identifying seasonal variations, and making informed decisions based on the data’s temporal structure. It plays a crucial role in predicting future trends and making data-driven decisions in a wide range of applications.
3.7 Decision Trees:
Decision trees are powerful tools in data mining used for both classification and regression tasks. They represent a flowchart-like structure where each internal node denotes a test on a specific attribute, each branch represents an outcome of the test, and each leaf node represents a class label or a numerical value. Decision trees are popular due to their simplicity, interpretability, and ability to handle both categorical and numerical data. They help in making decisions based on a set of rules learned from the data, making them valuable in various fields, such as business, finance, and healthcare. Decision trees are particularly useful for understanding complex decision-making processes and are a fundamental component of many machine learning algorithms.
3.8 Nomaly Detection:
Anomaly detection methods identify unusual patterns or outliers in the data, which can be indicative of errors or fraud.
3.9 Evaluation and Validation:
After applying data mining techniques, the results need to be evaluated to ensure their accuracy and reliability. Various metrics are used, depending on the type of analysis performed, to validate the models.
4. Challenges and Considerations
4.1 Data Quality: The accuracy and reliability of the results heavily depend on the quality of the input data. Noisy, incomplete, or irrelevant data can lead to misleading conclusions.
4.2 Privacy and Ethical Concerns: Mining sensitive or personal data raises ethical and privacy issues. Ensuring that data is anonymized and used responsibly is crucial to maintaining public trust.
4.3 Complexity and Interpretability: Some advanced data mining algorithms, especially in machine learning, can be complex and difficult to interpret. Interpretable models are essential, especially in applications where human understanding of the results is necessary.