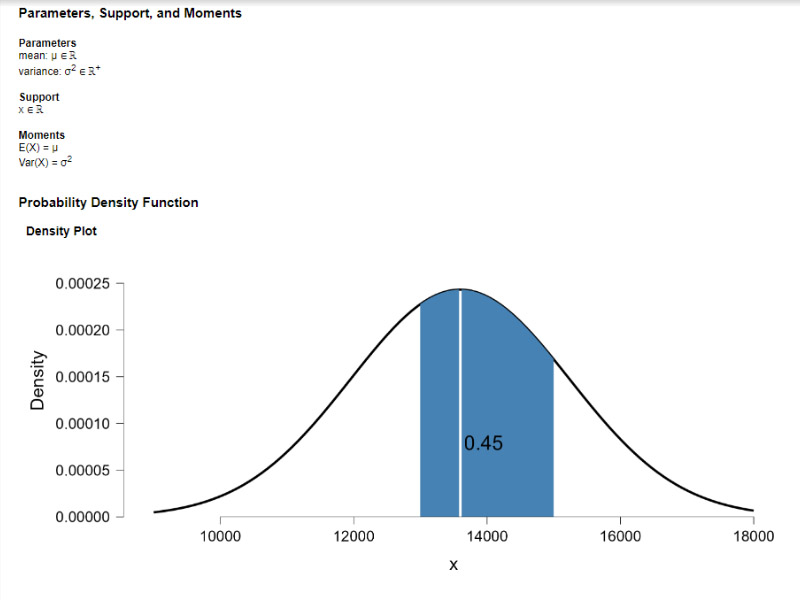
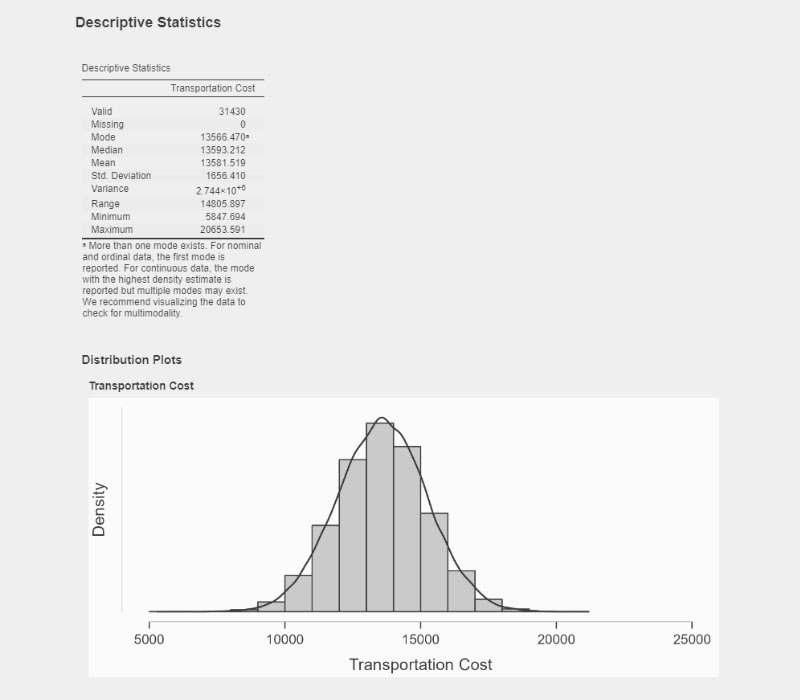
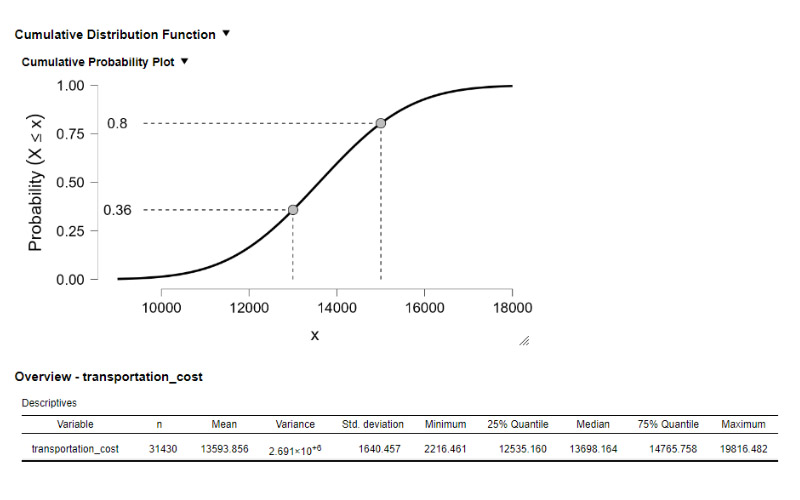
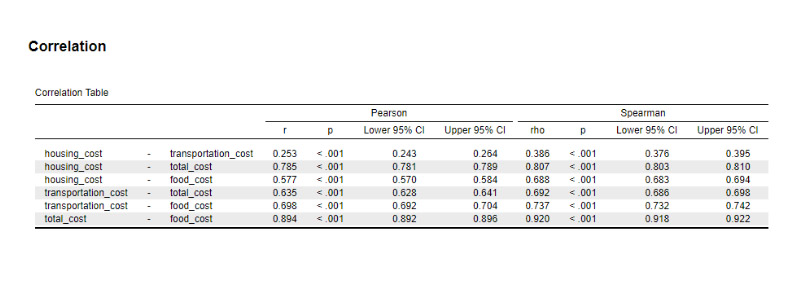
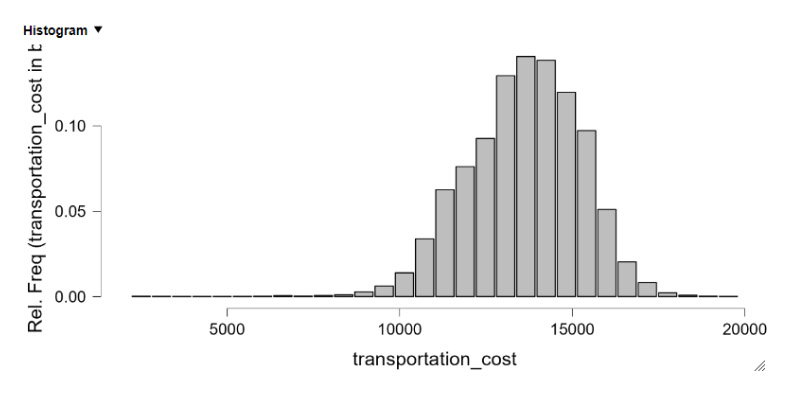
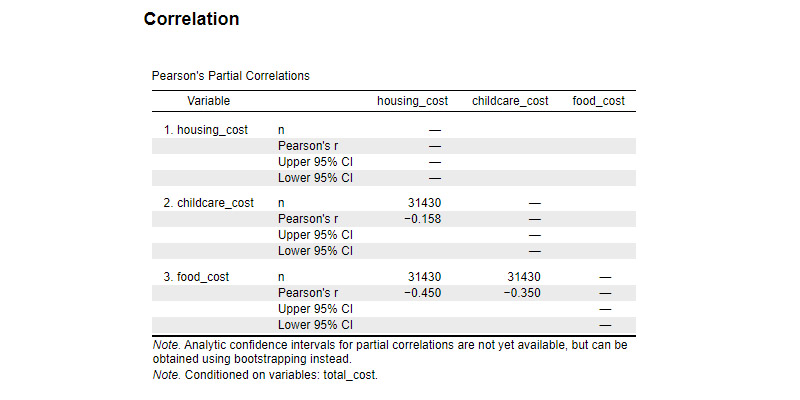
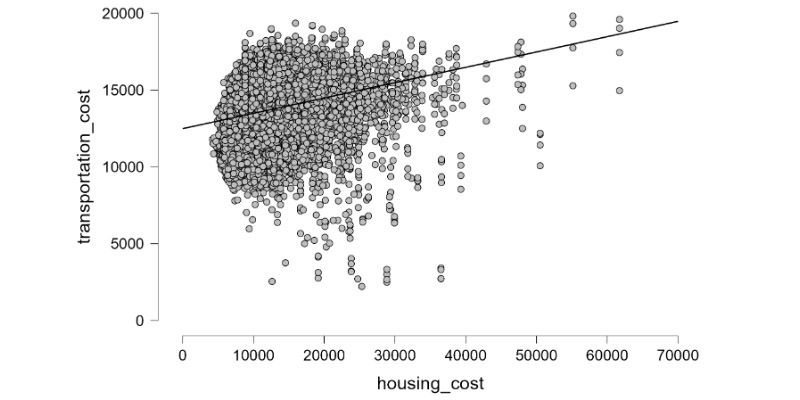
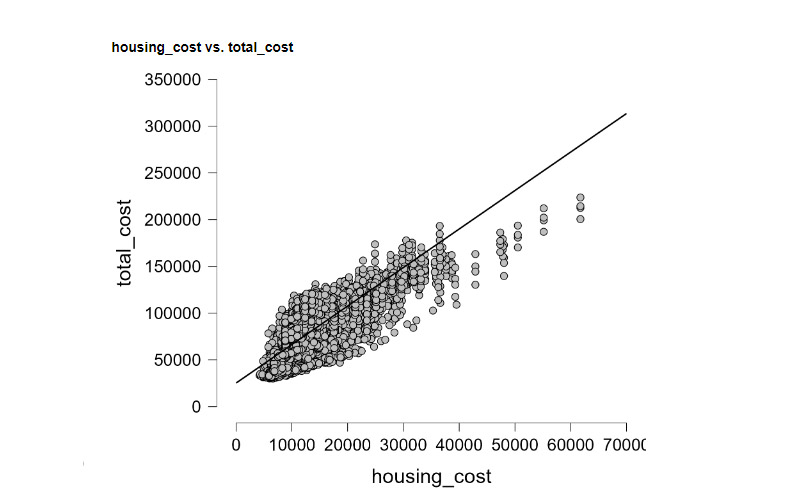
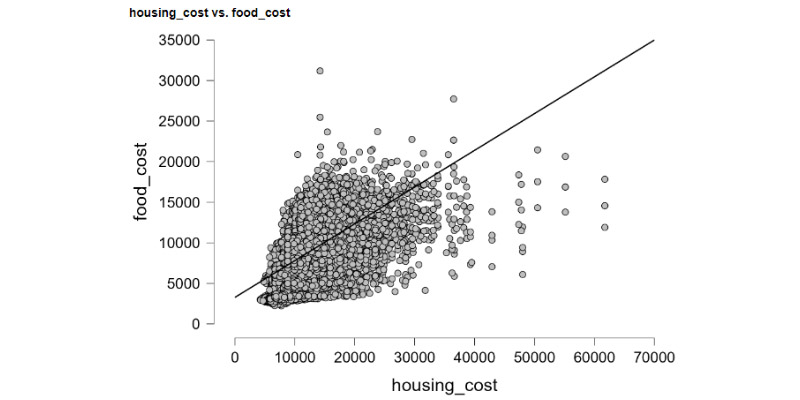
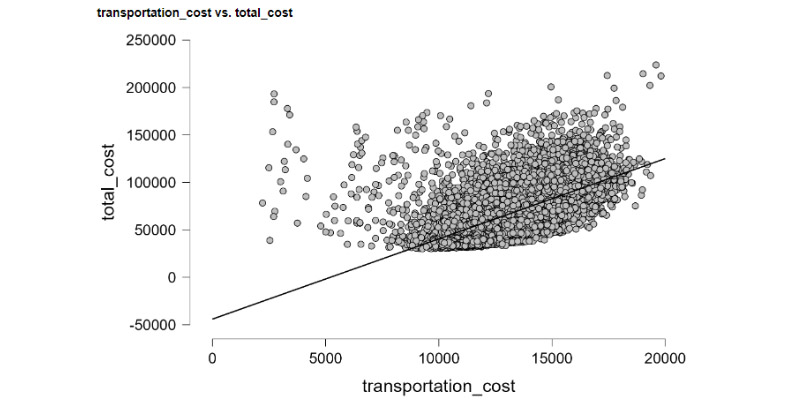
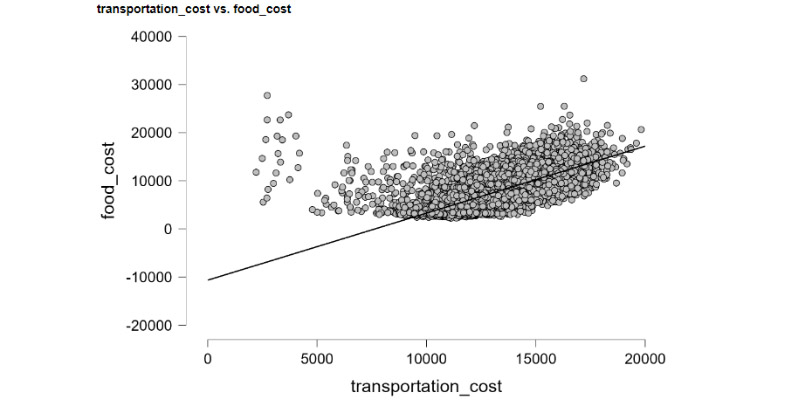
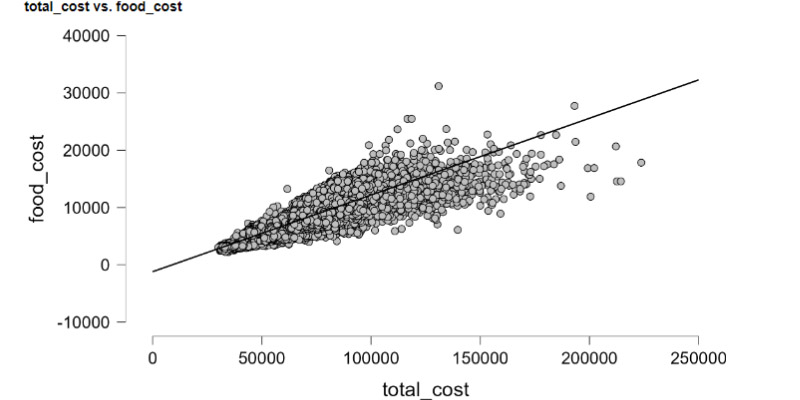
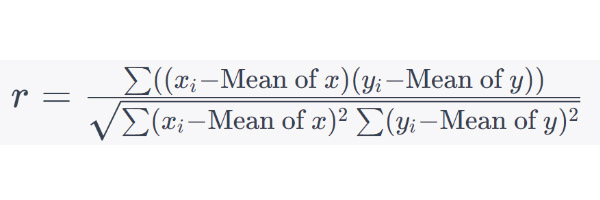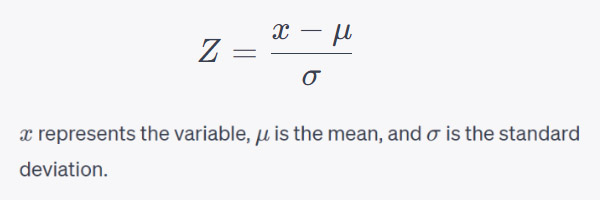In the world of data science and analysis, I feel right at home. I love exploring data, finding patterns, and turning numbers into meaningful stories. It's amazing how data scientists use their skills to bring clarity to complex information. Their dedication and curiosity drive innovation, and I find joy in solving challenges with every dataset. Working with data is not just a job; it's a thrilling adventure. I'm passionate about data science, and it's where I truly belong.